Примерно год назад на волне всеобщего хайпа вокруг ИИ-продуктов, мы решили создать сервис, который сможет превращать любое видео в короткий пост в Telegram без участия человека. Что из этого получилось, рассказываем далее
Хайп и технологии
Год назад, на волне хайпа вокруг ИИ, мы решили провести эксперимент — создать сервис, который превращает любое видео в короткий пост в Telegram без участия человека. Задача была простой: всё должно работать быстро и автоматически, при этом текст должен содержать не просто краткий пересказ, а структурированную информацию с ключевыми шагами, например, что нужно сделать, чтобы начать бегать. Мы не ставили коммерческих целей, а хотели сэкономить время на разборе видео и проверить свои возможности в работе с этой технологией.

Минимальный продукт, тесты
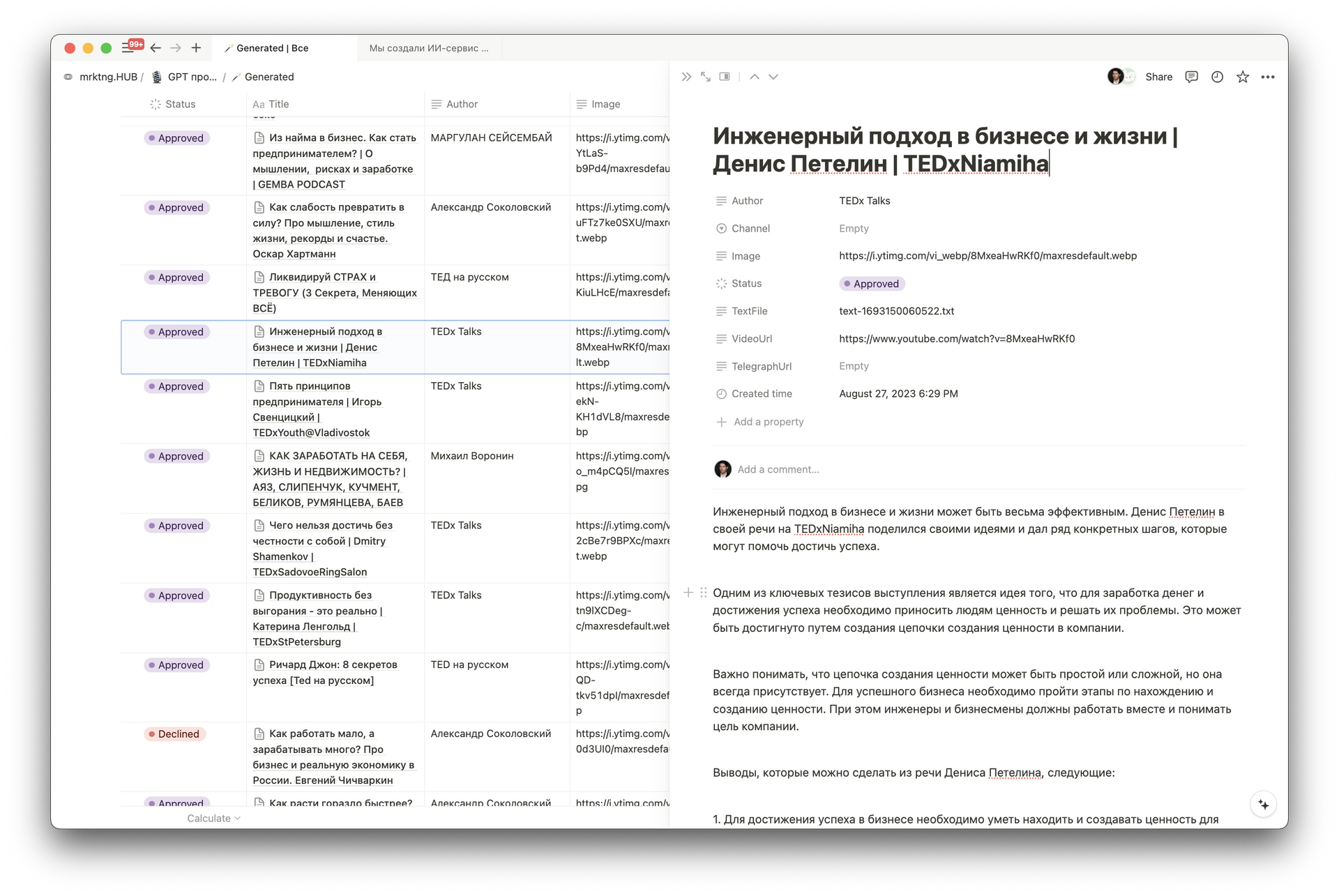
Чтобы упростить разработку, мы использовали готовые решения: Telegram-бот принимал ссылки, Notion служил базой данных, а сгенерированные статьи публиковались через Telegra.ph
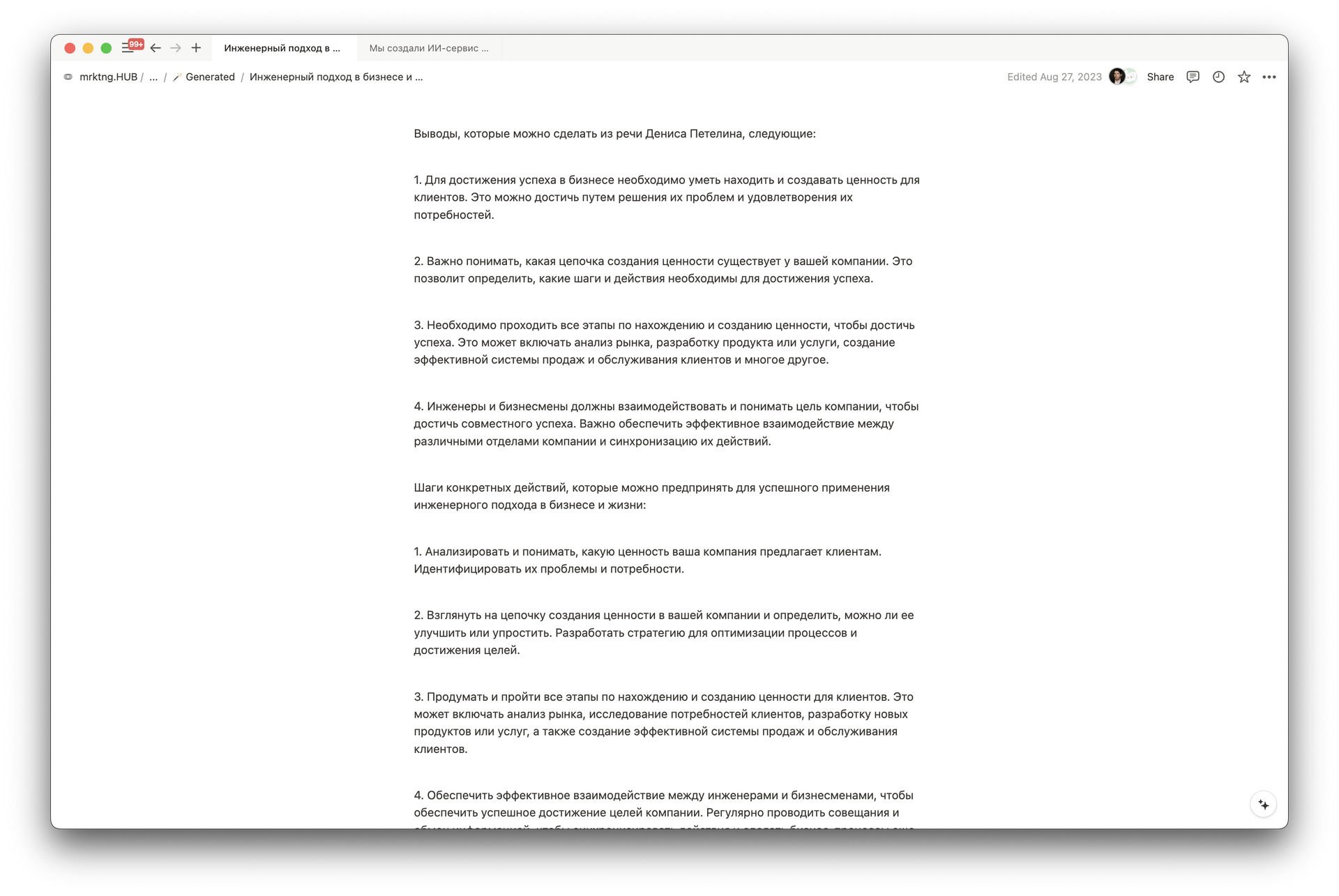
Сервис работал так: бот загружал видео с YouTube, извлекал аудио и отправлял его в AI Whisper для распознавания. Затем текст обрабатывался GPT-3.5, трансформировался по заданному промпту и автоматически публиковался в Telegram. Все промежуточные результаты и история обработанных видео сохранялись в Notion.
Обучение модели
Главной задачей было добиться не просто краткого, а точного и содержательного пересказа. Мы быстро убедились: механическое сжатие не работает — без акцента на смысл теряется ценность. Ключевым стало умение сохранить идеи, интонации и ход рассуждений, передав при этом суть разговора.
После множества итераций мы пришли к оптимальному формату: основные мысли выносятся отдельно, а пересказ строится вокруг них. Это делает текст структурированным, легко воспринимаемым и позволяет быстро понять содержание даже самых длинных видео.
Отладка, подготовка к релизу
Одной из ключевых технических сложностей стала работа с большими объёмами текста в GPT-3.5, где существует жёсткое ограничение на количество символов. Двухчасовые подкасты генерировали огромные массивы сырого текста, которые невозможно было обработать нейросетью целиком.
Для решения этой задачи мы разработали собственный алгоритм поэтапной нарезки и обработки: текст делился на смысловые блоки, каждый из которых обрабатывался отдельно, а затем — объединялся в единый пересказ. При необходимости цикл повторялся, пока итоговый текст не соответствовал лимитам и при этом сохранял связность и ключевые идеи.
Несколько итераций и ручная доводка позволили добиться стабильного качества обобщения, где сохранялись как структура оригинального контента, так и его смысловая глубина.
Алгоритм мог работать с текстами практически любого объёма, — в отличие от известного российского поисковика, который на больших объёмах выдавал ошибку и отказывался работать
Ставим проект на паузу
Сервис так и остался на уровне MVP. Перед релизом мы проконсультировались с юристами и подтвердили свои опасения: даже при глубокой переработке материалы продолжают подпадать под авторское право, что существенно ограничивает возможности их коммерческого использования.
Проект изначально задумывался как эксперимент — площадка для тестирования гипотез, а не бизнес-продукт. Главным вызовом стала работа с промптом: добиться стабильности и точности генерации на длинных сессиях оказалось сложнее, чем ожидалось. Мы осознанно не делали выводов о масштабируемости, поскольку обработали всего около 100 видео — этого недостаточно для объективной оценки устойчивости модели в реальных нагрузках.
Выводы и перспективы
Мы уверены, что созданное решение можно эффективно интегрировать в широкий спектр бизнес-процессов. Оно позволяет автоматизировать и упростить расшифровку звонков, совещаний, регламентов и обучающих материалов, что существенно экономит время сотрудников и снижает нагрузку на операционные ресурсы.
Работа над проектом не только подтвердила потенциал технологии, но и дала нам мощный импульс к развитию новых инструментов на базе GPT. Мы уже исследуем практические сценарии их применения и в ближайшее время представим первые кейсы, результаты и инсайты, которые помогут бизнесу работать быстрее, точнее и эффективнее.














трудочасов ежемесячно
исходя из фактических трудо-затрат
Большая Новодмитровская, 23
технологиях и будущем
